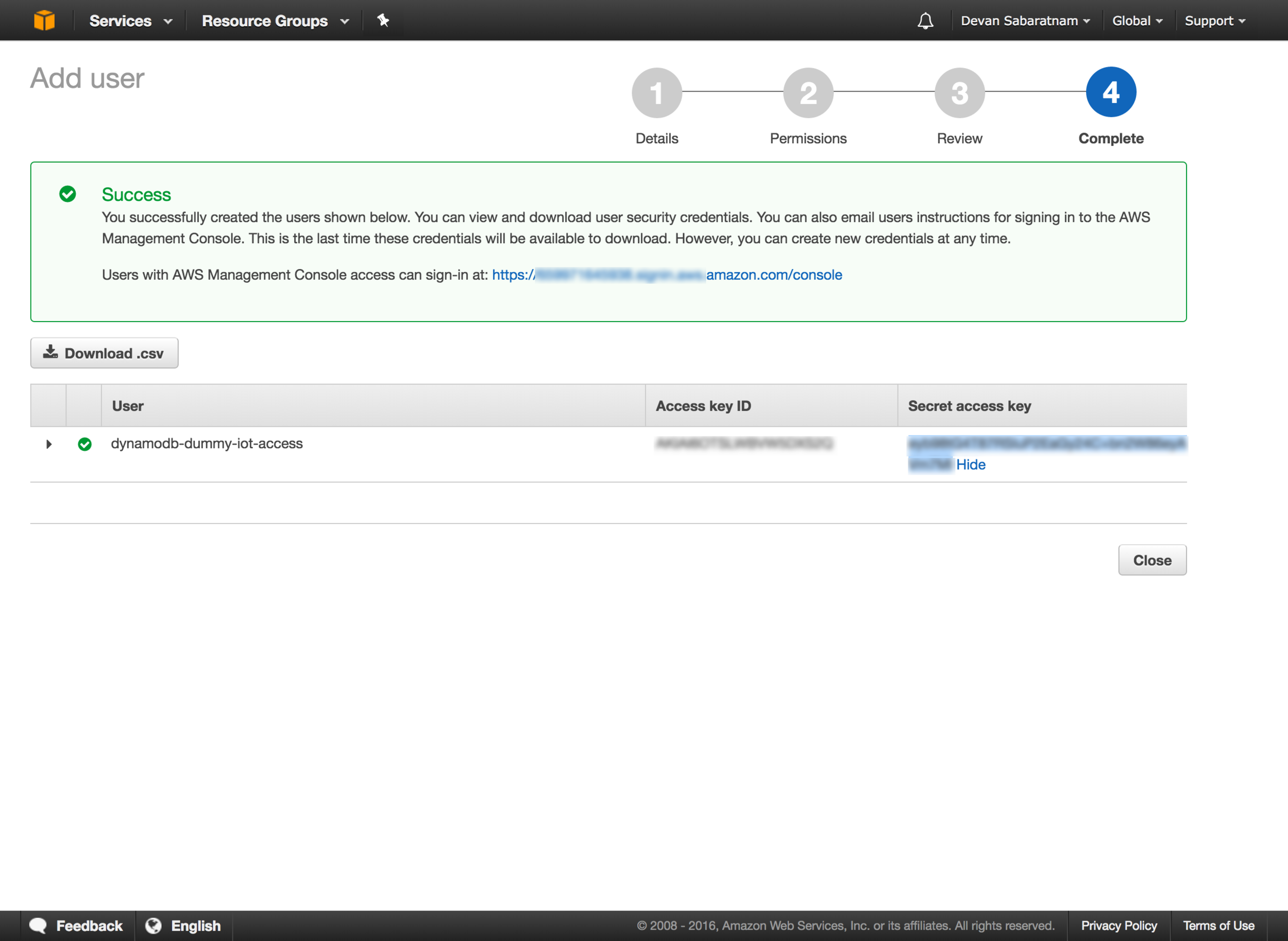
Now this page is IMPORTANT. Make a note of the AWS Key and Secret that you are given on this page, as we will need to incorporate it into our application below.
This is the ONLY time that you will be shown the key/secret for this user, so please copy and paste the info somewhere safe, and download the CSV file from this page with the information in it and keep it safe as well.
Download the Code
Next step, is to download the sample code from my GitHub page so you can modify it as necessary. Go to this link and either download the code as ZIP file, or perform a 'git clone' to clone it to your working folder.
First thing you need to do is to create a file called '.env' in your working folder, and enter these two lines, substituting your Amazon IAM Key and Secret in there (Note: These are NOT real key details below):
export AWS_KEY=A1B2C3D4E5J6K7L10
export AWS_SECRET=T/9rt344Ur+ln89we3552H5uKp901
You can also just run these two lines on your command shell (Linux and OSX) to set them as environment variable that the app can use. Windows user can run them too, just replace the 'export' prefix with 'set'.
Now, if you have Ruby installed on your system (Note: No need for full Ruby on Rails, just the basic Ruby language is all you need), then you can run
bundle install
to install all the pre-requisites (Sinatra etc.), then you can type
ruby faceapp.rb
to actually run the app. This should start up a web browser on port 4567, so you can fire up your browser and go to
http://localhost:4567
to see the web page and begin testing.
Using the App
The web page itself is fairly simple. You should see a live streaming image on the top center, which is the feed from your on board camera.
The first thing you will need to do is to create a collection by clicking the link at the very bottom left of the page. This will create an empty collection on Amazon's servers to hold your image data. Note that the default name for this collection is 'faceapp_test', but you can change that on the faceapp.rb ruby code (line 17).
Then, to begin adding faces to your collection, ask several people to sit down in front of your PC or table/phone, and make sure their face is in the photo frame ONLY (Multiple faces will make the scan fail). Once ready, enter their name in the text input box and click the 'Add to collection' button. You should see a message that their facial data has been added to the database.
Once you have built up several faces in your database, then you can get random people to sit down in front of the camera and click on 'Compare image'. Hopefully for people who have been already added to the collection, you should get back their name on screen, as well as a verbal greeting personalised to their name.
Please note that the usual way for Amazon Rekognition to work is to upload the JPEG/PNG photo to an Amazon S3 Bucket, then run the processing from there, but I wanted to bypass that double step and actually send the photo data directly to Rekognition as a Base64 encoded byte stream. Fortunately, the aws-sdk for Ruby allows you to do both methods.
Lets walk through the code now.
First of all, lets take a look at the we page raw HTML itself.
https://github.com/CyberFerret/FaceRekognition-Demo/blob/master/views/faceapp.erb
This is a really simple page that should be self explanatory to anyone familiar with HTML creation. Just a series of names divs, as well as buttons and links. Note that we are using jQuery, and also Moment.js for the custom greeting. Of note is the faceapp.js code, which does all the tricky stuff, and the links to the JPEG camera library.
You may also notice the <audio> tags at the bottom of the file, and you may ask what this is all about - well, this is going to be the placeholder for the audio greeting we send to the user (see below).
Let's break down the main app js file.
https://github.com/CyberFerret/FaceRekognition-Demo/blob/master/public/js/faceapp.js
This sets up the JPEG Camera library to show the camera feed on screen, and process the upload of the images.
The add_to_collection() function is straightforward, in that it takes the captured image from the camera, then does a post to the /upload endpoint along with the user's name as the parameter. The function will check that you have actually entered a name or it will not continue, as you need a short name as a unique identifier for this facial data.
The upload function simply checks that the call to /upload finished cleanly, and either displays a success message or the error if it doesn't.
The compare_image() function is what gets called when you click the, well, 'Compare image' button. It simply grabs a frame from the camera, and POSTs the photo data to the /compare endpoint. This endpoint will return either an error, or else a JSON structure containing the id (name) of the found face, as well as the percentage confidence.
If there is a successful face match, the function will then go ahead and send the name of the found face to the /speech endpoint. This endpoint calls the Amazon Polly service to convert the custom greeting to an MP3 file that can be played back to the user.
The Amazon Polly service returns the greeting as a binary MP3 stream, and so we take this IO stream and BaseEncode64 it, and place it as an encoded source link in the <audio> placeholder tags on our web page, which we can then do a .play() on the element in order to play the MP3 through the user's speakers using the HTML5 Web Audio API.
This is also the first time I have placed encoded data in the audio src attribute, rather than a link to a physical MP3 file, and I am glad to report that it worked a treat!
Lastly on the app js file is the greetingTime() function. All this does is work out whether to say 'good morning/afternoon/evening' depending on the user's time of day. A lot of code for something so simple, but I wanted the custom greeting they hear to be tailored to their time of day.
Lastly, lets look at the Ruby code for the Sinatra app.
https://github.com/CyberFerret/FaceRekognition-Demo/blob/master/faceapp.rb
Pretty straightforward Sinatra stuff here. The top is just the requires that we need for the various AWS SDK and other libraries.
Then there is a block setting up the AWS authentication configuration, and the default collection name that we will be using (which you can feel free to change).
Then, the rest of the code is simply the endpoints that Sinatra will listen out for. It listens for a GET on '/' in order to display the actual web page to the end user, and it also listens out for POST calls to /upload, /compare and /speech which the javascript file above posts data to. Only about 3 or 4 lines of code for each of these endpoints to actually carry out the facial recognition and speech tasks, all documented in the AWS SDK documentation.
That's about all that I can think of to share at this point. Please have fun with the project, and let me know what you end up building with it. Personally, I am using this project as a starting block for some amazing new features that I would love to have in our main web app HR Partner.
Good Luck, and enjoy your facial recognition/speech synthesis journey.