Photo by Museums Victoria on Unsplash
This is probably an out of date concept these days, however if you ever ran a traditional business back in the 70’s, 80’s and 90’s as I did, one of the most frustrating things ever was trying to get my banking done over the counter.
Almost all businesses have to have cash floats, or make deposits etc. to ensure cashflow stays strong, or perhaps talk to a manager to make certain arrangements. I know I had to do this many, many times during my business life over the decades, however it always flummoxed me as to how bad the experience was.
You see, in Australia, banks didn’t really open their doors until about 9am. Then they would shut early - around 4pm, citing that their staff needed the extra time at the start and end of each day to cash up and reconcile etc.
The big problem with that, was that most business people couldn’t visit the bank except:
Before they opened their own doors early in the morning, or
After they closed up shop at the end of the day, or
During their lunch break
Because (1) and (2) was practically impossible, you used to get a massive rush during (3) when almost every business in town was in the bank to try and get things done.
Here is a rough timeline graph of the bank’s chosen working hours vs the customer demand during those hours:
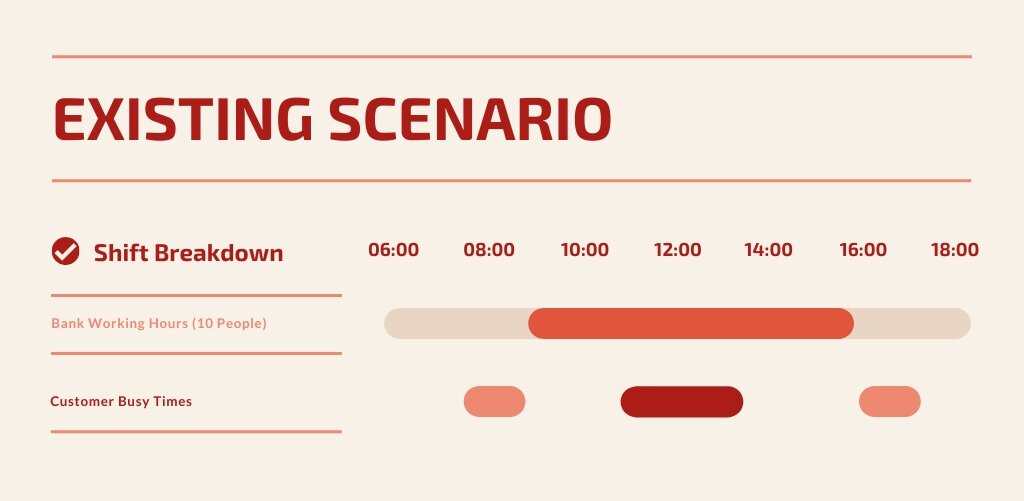
As you can see, a lot of frustrated people on either end, and a lot of overworked, harried bank staff in the middle trying to deal with the uncommon rush.
Why didn’t banks ever implement a split shift system?

They could have easily split their staffing in half, and have half the team come in earlier in the morning to open up and do the morning cash processing, and offer counter service to businesses who needed to get their cash floats before starting the day.
Then, they could have had a ‘late team’ come in later in the morning to help the morning team cover the mid-day rush, and work later to finish cashing up and deal with businesses coming in after closing to deposit their daily takings.
They would still have had a full team on for the lunch rush (which would be lessened by taking care of the customer needs on either end of the day, with no additional staffing costs involved.
I would assume that workers with kids in school would prefer to work the morning shift and finish working when it was time to pick up their children from school. Alternatively, people who were studying or partying may wish to sleep in a little later and work into the evening.
As I said, this is probably all redundant now, in the cashless economy and online banking world, however it is something that I always thought about when I walked into a bank to do business, but ended up leaving in frustration and with a negative taste in my mouth.